本文基于 JDK 1.7 的源码进行分析。
概述
HashMap 是我们经常使用的容器,它是基于哈希表的 Map 实现。HashMap 允许存在 Null 键和 Null 值,它是非线程安全的。此类并不保证映射的顺序,特别是它不保证顺序恒久不变。
在 JDK 1.7 中,HashMap 的内部是由数组+链表来实现的。数组是 HashMap 的主体,链表则是为了解决哈希冲突而存在的。也就是说 HashMap 中解决哈希冲突采用了链地址法。
HashMap 原理
HashMap 的构造方法
HashMap 有四个构造方法:
HashMap(int initialCapacity, float loadFactor)HashMap(int initialCapacity)HashMap()HashMap(Map<? extends K, ? extends V> m)
这里介绍一下两个重要的参数:initialCapacity 初始容量和 loadFactor 加载因子。
容量就是哈希表中桶的数量,初始容量就是哈希表在创建时的容量,记载因子就是哈希表在其容量自动增加之前可以达到多满的一种尺度。
当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
在 HashMap 中,默认的 DEFAULT_INITIAL_CAPACITY = 16,DEFAULT_LOAD_FACTOR = 0.75f。
HashMap 的阈值也就是可以容纳的数据量为:
1 | threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); |
HashMap 数据存储
HashMap 中的数据是通过 Entry<K,V>[] table 树组来存储的,它的基本数据单元是 Entry:
1 | static class Entry<K,V> implements Map.Entry<K,V> { |
上面也提到过,HashMap 是由数组+链表来实现数据存储,数组中保存的是链表的头部元素。
可以用下面的图来直观一点表示:
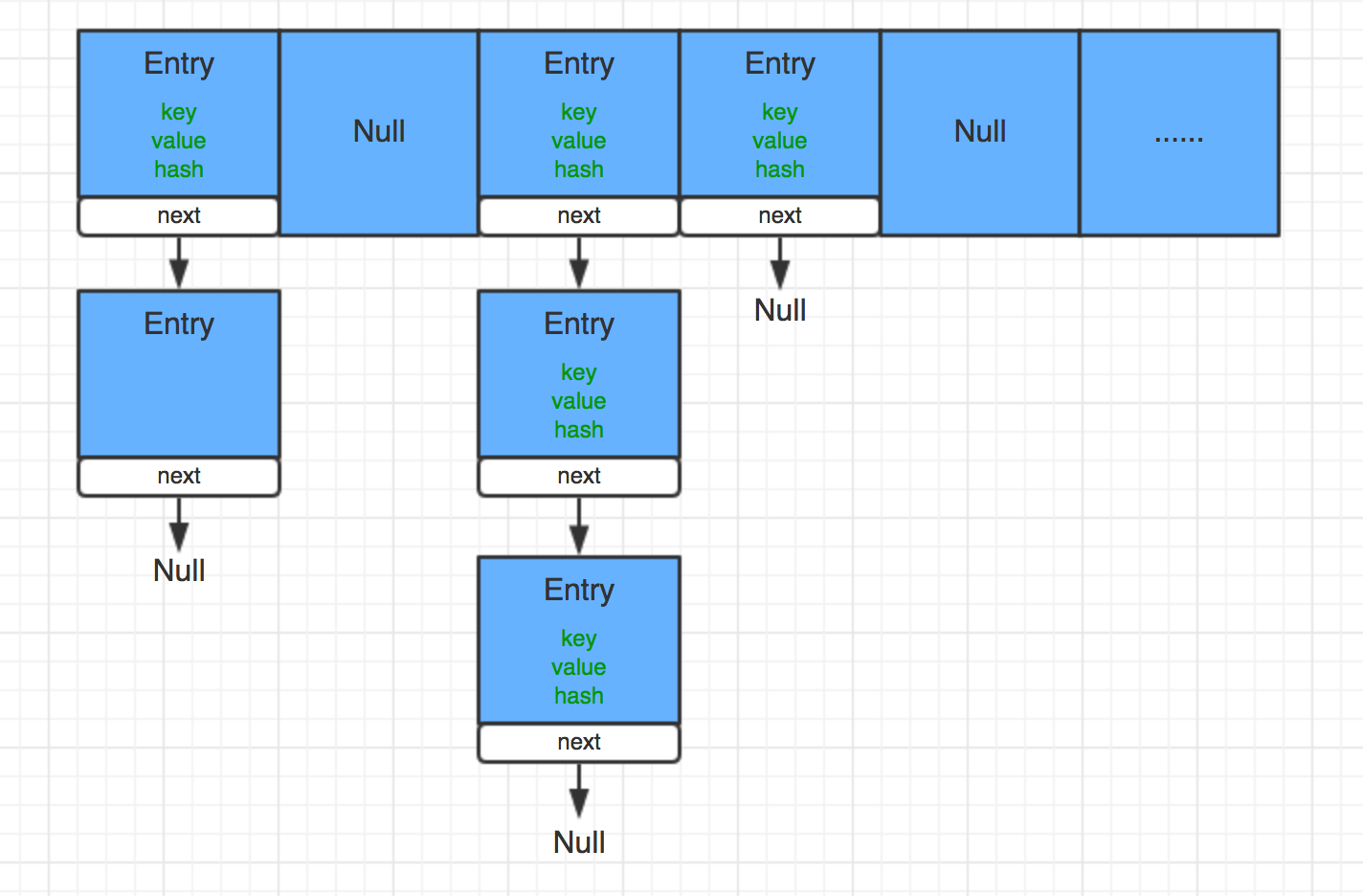
HashMap put 方法
put 方法的返回值为 HashMap 中已有的该 key 值对应的值,如果没有相同的key,返回 null。
1 | public V put(K key, V value) { |
这里涉及下面几个操作:
- 根据key求哈希值;
- 根据哈希值得到index,也就是在数组中的存储位置
- 添加新的 Entry
1 | void addEntry(int hash, K key, V value, int bucketIndex) { |
容量扩容
1 | void resize(int newCapacity) { |
HashMap get 方法
这个过程也比较简单:
- 根据 key 计算哈希值
- 根据哈希值获取在数组中的位置
- 遍历该位置的链表,直到找到该key对应的 Entry,返回 value
1 | public V get(Object key) { |
HashMap keySet() entrySet() 方法
keySet() 和 entrySet() 实现原理相同,这里我么只介绍一下 entrySet()。
1 | public Set<Map.Entry<K,V>> entrySet() { |
这里的关键点在 entrySet 变量,但是我们通过看源码发现一个奇怪的事情,代码中对 entrySet 只有读取的操作,并没有发现写入数据的操作。
我们来看一下 EntrySet 的实现:
1 | private final class EntrySet extends AbstractSet<Map.Entry<K,V>> { |
找到了问题的重点,EntrySet 类重写了 iterator() 方法,生成了 EntryIterator 对象。
1 | private final class EntryIterator extends HashIterator<Map.Entry<K,V>> { |
HashIterator 是 HashMap 的一个内部类,实现了 Iterator 接口,对于迭代器的各种操作,都是基于 HashMap 的变量 table 来进行的,这也就是为什么我们发现没有对 EntrySet 写入数据的原因。
HashMap 的遍历
第一种:获取 keySet 遍历,根据 key 再通过 get 方法获取 value
1 | HashMap<String, String> hashMap = new HashMap(); |
第二种:获取 entrySet,根据Map.Entry 获取key和value,较第一种方法效率高,一次获取可以得到key和value。
1 | HashMap<String, String> hashMap = new HashMap(); |
第三种:获取 entrySet 的迭代器,然后进行遍历,其实 foreach 的实现也是基于迭代器 iterator() 的。
1 | Iterator iterator = hashMap.entrySet().iterator(); |